In a "Virtual Enterprise", some company, the ultimate consumer, assembles a temporary consortium of partners and services for some purpose, which may be a temporary special request, or an ongoing goal of fulfilling orders, or in order to take advantage of a new resource or market niche. The general rationale for forming a VE is to reduce costs and time-to-market and increase flexibility and access to new markets and resources. As much as possible, individual companies focus on core competencies and mission critical operations: everything else is outsourced. Partners and resources are found as needed and the process changes to respond to market forces.
A powerful idea for achieving VEs is that of processes dynamically constructed out of available Internet-based services as needed at runtime. In the late 1980's, Marty Tenenbaum talked about a "sea of services" on the Internet that would facilitate VEs. Now that we have web services, this idea has great potential.
A key method of achieving this goal is to create a set of standards and conventions that would allow software to discover and integrate automatically partners, markets, and services as needed, without prior agreement. By "automatically", we mean that the software can perform these functions without new code being written and with no, or minimal, runtime direction by humans. Such autonomic software is essential for scaling. With such technology, Companies could then leverage a global infrastructure formed by this set of standards and conventions to respond quickly to changing conditions, forming multiple-company special projects that last over widely varying periods of time. Over the years, many people have had the same vision: services and requirements become sufficiently standardized that the world becomes one big open just-in-time supply chain.
Consider the abstract scenario of supply chains. At any point in the process, a supplier may be a consumer. In response to a request for quote from supplier-1, supplier-2 may in turn request quotes from supplier-3 and supplier-4. Anticipating those quotes, because those suppliers in turn may be requesting quotes from other suppliers, supplier-2 may give supplier-1 a preliminary quote, which may be accepted, but then later supplier-2 may need to reneg on the quote because of the responses from supplier-3 and supplier-4. Obviously this process may recurse, and not sequentially as in a chain. Let us call this a Recursive Supply Network (RSN). It is a virtual enterprise because the process consists of different companies providing different services and products to each other at different times in order to successfully enact a process.
A RSN, and VEs in general, must handle contingencies and new opportunities. Suppose that a component fails to be shipped on time: what can be done to recover and how should recovery be supported. Does one need to find another shipper or another supplier? A RSN requires status monitoring and control: a distributed process plan should be continually monitored and changed as necessary. Were we able to able to support such a dynamic real-time virtual enterprise, business supply chains would be faster and more efficient, and projects would complete faster and more cheaply. All distributed processes, including even large-scale civil engineering, would be better managed. Moreover, this vision can be extended to personal affairs in which people make travel, dinner, and sport plans with each other, ordering (and changing/canceling) various business services in the process.
Instead of this vision, companies have traditionally used RPCs and private networks based on pre-arranged legal contracts. A major innovation was the use of a standard EDI25 along these private channels, doing business only with other companies with which they already have contracts. But suppose one has a composite service that includes shipping and one discovers a shipper with superior service for the immediate application? Should the supply process not immediately take advantage of this efficiency? One can also easily imagine new ways of doing business: for instance with third party brokers such as today's e-auction sites that do not require end-point contracts.
Since Tenenbaum's proposal, we have had the commercialization of the Internet with HTTP/HTML protocols that allowed "screen scraping". Because screens were complex and could change, companies arose that specialized in screen scraping in certain domains, selling their meta-services to consumers of the domain service, such as Yodlee1 selling aggregation of financial information. "Web services", especailly those built around WSDL2 and SOAP, as surveyed in [Curbera], are proposals that would eliminate such intermediaries and move us toward VEs.
Our use of the term "web services" does not mean just any standard way to access business logic. It does mean a way of publishing an explicit, machine-readable, common standard description of how to use a service and access it via another program using some standard message transport. In particular, the use of SOAP and WSDL has been strongly embraced by industry and has become a major standard for such web services. WSDL has had fast industrial acceptance, not in spite of its simplicity in comparison with more advanced systemic standards such as ebXML6, but because of it.
The importantance of SOAP and WSDL is that they offer the possibility of a simple industrial standard for reading what input and output messages a service accepts and sends, and then sending those messages over a standard transport. This loose coupling means it is irrelevant what kind of client or server software is at either end. SOAP and WSDL provide an API-like abstraction from software, in a simple lightweight format, that industry has long needed. Also, SOAP and WSDL are simple open standards (like HTTP and HTML) with plenty of available tools. These tools are useful as well for other purposes and are becoming de facto standards in themselves. In contrast, EDI and similar systems, although perhaps better designed business interchange standards, required expertise and special tools as well as much longer construction times.
However, there is a strong risk of disenchantment with WSDL. The object-oriented community with experience in distributed transactions has already pointed out some of the problems with these standards[Vinoski]. Moreover, there is has been an expectation that we will be able to achieve the goal of discovering services when we need them, and, what is more, assembling them into new composite services, dynamically on-the-fly, as needed. We show that WSDL-related technologies, such as WSCI22, WSCL5, XLANG8, and WSFL11 (the latter two having morphed into BPEL4WS17), which collectively we refer to as "WSxL" standards, are inadequate for dynamic discovery and integration, and thus inadequate for VEs. We also discuss the issues in providing the missing functionality.
How is one to discover a web service "automatically, on-the-fly"? There are two parts to discovery: search and use. In this section, we examine discovery of new services: usually considered the function of Universal Description, Discovery and Integration (UDDI)18.
The goal of any service directory, including UDDI, is to enable automatic search of desired services. UDDI also purports to provide sufficient information for the use of previously unknown services, freshly discovered [Trivedi], just as XML was previously touted as enabling the understanding of previously unencountered data and information[Petrie 1998].
However, UDDI does not provide service descriptions, even in theory. UDDI is structured to provide meta-metadata about services. A service is declared to be described in WSDL by virtue of a UDDI tModel that includes a keyValue="wsdlSpec", and a tModelKey that refers to a unique identifier for WSDL descriptions in a taxonomy of kinds of service descriptions. The WSDL, which is to be found on a site maintained by the the service provider, itself contains metadata about the service: a description of the service and how to use it. The UDDI description is a description of the kind of service description. The UDDI description could have alternatively said that the service was described by a RosettaNet9 Partner Interface Process, or an EDI process, but the UDDI description itself does not contain the service description.
Even in theory, UDDI support for automated search is severly restricted. An official UDDI registry comes with a default set of taxonomies, to which other taxonomies can be added; i.e., registered. Suppose our VE is a not a travel agency itself but does occasionally need to perform logistics as part of its operations. We want our automated software to book a flight (the usual example). We would like our software automatically to go to a UDDI, for example, IBM's UDDI at https://uddi.ibm.com/ubr/registry.html and ask the computer equivalent of "Are there any web services that book flights?"
In order to use the Find function, the discovery program would have to query a UDDI node for a set of taxonomies. The reader can try this themselves by clicking on Find, and use the Advanced Search to Find a Service. Most of the existing taxonomies are not of web services, but rather business entities. But suppose there were. One solution to this are really good taxonomies of services. The IBM UDDI is using one called WAND that seems better than the defaults, but which does not allow search at other UDDI nodes since the taxonomy is proprietary. (There are a number of implementation issues ignored here, which arise because it is in the vendors' interests to make each UDDI node as unique as possible.)
The next problem is that the taxonomonies are not machine readable: there is no standard syntax much less semantics for taxonomies. New taxonomies will be a mystery to our agent. But suppose the software agent were somehow programmed to read even the new taxonomies, could select a web service taxonomy and could then use it for selection. Then the agent could send a query to the UDDI node asking for web services that are classified using this taxonomy.
But services are not classified by their WSDL operations: we cannot ask for a service that books flights. This is because as well as business descriptions and taxonomies, service descriptions are not stored in in UDDI, but rather only their pointers. And since UDDI does not also provide distributed search functionality over these distributed service descriptions, one cannot do any more than discover which services have been registered with a given taxonomy. Because it only points to descriptions, UDDI uses the SEP principle: Somebody Else's Problem. While possibly a good design decision, this means that UDDI falls short in the semantic description of services necessary for automated search.
In this case, the problem is passed over to WSDL. Our software agent can only look for "travel" services. The reader should look for a Service Name starting with "Travel" using Locator Category (Taxonomy) "UNSPC" and leave the other values blank. The first Service Name returned will be "Travel Adventures Unlimited". Clicking on this name gets you a page showing the UDDI registry entry. Click on Details and the Access Point Address to get a list of WSDL service operations, which is not informative. (If you haven't followed along, all of the operation names are similar to "P3Typex".) Clicking on "P3Type3" will get you an web page i/f to the SOAP message showing you that this operation has to do with "airlineID". A software agent would go directly to the WSDL (click on "Service Description" to see this) in order to discover that the part name for the Input Message for this operation is "airlineID" but what is expected for a response is a little mysterious since the output message part name is "body". In fact, none of the operations actually book a flight. (That this is not surprising is discussed later.)
Suppose that UDDI, or some other mechanism, were to provide distributed search of WSDL descriptions. Would an automated software agent be able to use those descriptions to search for a desired service? The above example leads one to suspect not. Let's look at WSDL example from at http://www.xmethods.com/. Suppose we are looking for a service to find telephone numbers in Sweden, a fairly trivial service. Could we automatically discover the representative service called "ISearchSwedishPerson"? First, not with UDDI. But could we with an agent that searched this "xmethods" site?
There are two problems with such a search for a service. One is that this name is not the WSDL service name, which is "ISearchSwedishPersonservice". The more serious problem is that it would take a smart search engine to realize what this service does, especially since the semantics even for humans is encapsulated in a C programming style of capitalizing the beginning of otherwise co-joined words.
But let's suppose the program is a good guesser and now
decides to examine the
the actual WSDL description at
http://www.marotz.se/scripts/searchperson.exe/wsdl/ISearchSwedishPerson,
in order to figure out if this service will be useful for the intended
purpose. This service has five operations:
If there were reference to a standard taxonomy or ontology (not just those for registering services in UDDI), software would have a pretty good chance of understanding at least the term "City". If there are type specifications, they may refer to XML schemas that could give further clues about the semantics of the messages and thus service operations. So it is not completely hopeless, but it will be difficult to discover new services.
Some standard taxonomy, or an ontology, will be needed. Service discovery requires semantics for service operations and messages. This might be something elaborate as DAML-S3, TAP4, Rosettanet, or even just some informal industry de facto standard terminology. In particular, DAML-S provides a well-designed solution to the problem of providing semantics for distributed search16 of web services. While DAML-S is a very good and important solution, it has two weaknessnes. First, it only provides information at the service level and not at the WSDL operation level. Second, it may be too heavy for industrial purposes. UBL28 is more likely to be adapted as a semantic solution by industry.
The second point is that such terminology is more likely to be agreed upon at the level of message part names such as "City", rather than operation names such as "HTMLSearchAddress". "City", is not defined today in DAML-S, for example, though it could be. The example shows that even if automatic discovery is not possible today, it could be in the near future even with existing WSDL but the discovery programs will have to be smart enough to parse XML schemas using the taxonomies that provide service operation semantics.FOOTNOTE: The RPC thinking of WSDL developers will have to change. The output message of "HTMLSearchAddress" is named "HTMLSearchAddressResponse" and its only part name is "return". This unfortunate naming methodology is quite common in WSDL. And the type of the value is just "string". It will be impossible for a program to determine what this web service is returning. It would have been so much better had the part name been something like "telephone-number". The part name of another message in another operation is simply "number". Again, this is too generic to be meaningful to a discovery program unless it is almost as smart as a human. But this is not the fault of WSDL. A "return" can easilly befined as a complex XML type, that can be parsed automatically by software reading the description. This is a methodological and conceptual problem.
The larger problem is that UDDI passes off the problem of a service description adequate for search to WSDL. The designers of WSDL clearly intended the service directory to solve this problem. Stalemate. WSDL descriptions will have to be expanded and the functionality of UDDI will have to included distributed search. WSDL does pose a technical problem for any UDDI++ allowing distributed search for WSDL operations. XML conventions allow an operation to be indirectly referenced by a URI, which may be a URL, or a global URN. If the latter, they may be no standard way of locating the operation (or any other WSDL component). How to extend the service descriptions so that a UDDI++ would enable a search at the level of operations and messages is an open issue.
If we consider the two WSDL examples above, we can see that descriptions sufficient for discovery involve descriptions sufficient for use. How do we know what operations we are looking for if we don't know what the operations actually do? Knowing what the operations do presumes knowing how to use them. That is why we empahsize that discovery involves both search and use.
If the search is successful, then the service is understood to be applicable for the intended purpose. What may not be understood are the conditions for using the service. Without machine readable descriptions, web services cannot really be used by a software program without a human first reading the web page descriptions for each web service and its operations, and writing code.
We can illustrate this best by starting from scratch and making an existing web-based service a web service with SOAP messages described by WSDL. In such a case, we do not inherit naming and semantic issues. We can then discover higher-level problems with WSDL. In the FX-Agents project, we have chosen a restaurant from the waiter.com restaurant web site and attempted to reimplement it via SOAP and WSDL. Even in this simple case for a given restaurant, one discovers that one needs to understand how to execute a sequence of operations in order to use the service. One must select a restarurant, get the menu, choose an entree, make selections about the entree, and then execute the regular payment and delivery operations. A UDDI/WSDL++ technology must provide machine readable instructions for sequencing service operations.
Over and above this, one finds less obvious but important problems with WSDL as a formal representation for dynamically discovered services:
There are also no message semantics are defined at all for concepts that might routinely be associated with services, such as reason for denial of service or even a simple concept such as "service-provider". There is no provision for correlation of replies from multiple queries of restaurants as to delivery speed.
WSDL technology makes no commitment to representing these service concepts. WSDL developers currently have two choices: either don't express the conditions or express them in an "ad hoc" manner. The latter course is often chosen and works quite well in private practice (not listed in a UDDI), such as the case of "Dollar Car Rentals"23. The issues of authorization and payment are ignored. Cancellation is achieved via an ad hoc operation but this approach is will not scale since every discovery program will have to somehow be programmed for each new payment, authorization, and cancellation operation.
There also should be, for automatic use, explicit tags referring to pre- and post-conditions for use of the service. For instance, that the driver should be over 18 years of age and possess a valid drivers license. And that after the car is reserved, perhaps the company will deliver it to a certain spot by a certain date. DAML-S does allow specification of such conditions, and possibly including such information separately from WSDL may ultimately be the only solution.
WSDL has great promise because it is so simple but must become enriched by technologies analogous to style-sheets and XML schema. Perhaps a taxonomy will become standardized through the use of WSIL10. We suspect the most likely outcome is that particular WSDL operations for special functions such as payment, authentication, and cancelation will become standardized through business implementation and convention.
The lack of representation in WSDL for alternatives, for conditions for use of the service, and of side-effects resulting from use of the service, are extremely serious limitations for engineering business processes. These descriptive lacunae are sufficient to prevent the automatic and dynamic use of previously unknown services in a VE, and make a recursive supply network impossible as new component sources cannot be found on the fly. But the opportunity for interesting research becomes greater when one considers web service integration, necessary for VEs.
Assuming a UDDI/WSDL++ with expressive power sufficient to discover and understand their use dynamically, we would like to integrate some set of services in order to accomplish a goal, such as a complex travel plan, or a RSN. Our dessiderata for VEs include two fundamental principles. Any pubically registered web service can be consumed:
Service composition is a sub-issue of integration: how to make a set of services into a single visible service. Several systems do an admirable job of providing composition, including WSFL, BPEL4WS, and Self-Serv[Benatallah]. While we acknowledge that composition may be an important topic for some VEs, wrt to VE's, we are most concerned with dynamic service integration, which may not even be compatible with composition.
Integration architectures may be evaluated not only on the basis of the two fundamental principles , but also on the following three dimensions:
In the simplest case of service integration, all of the control, status, and state information can be managed by a central program using direct control. For a given application, such direct control is not a bad solution, and can be accomplised without violating our pinciples and may lie anywhere on any of the dimensions above.
However, the internal workflow approach is not sufficient if the VE is an RSN. If one of the web services accomplishes its promised ultimate output by consuming other services, these are completely hidden from the ultimate consumer, and thus cannot be monitored, much less controled. For an RSN, we require some measure of monitoring and control of the RSN. One way of achieving this is a workflow-like flow of control, which usually means that a graph of possible transitions among all of the services concerned is developed prior to runtime. This approach will violate the principles above to some degree as it will not allow services and providers to be used that were not specified in the graph. However, graph-based architectures vary in the degree to which they allow runtime flexibility. All allow specific service providers to be chosen at runtime from a pre-existing set of partners.
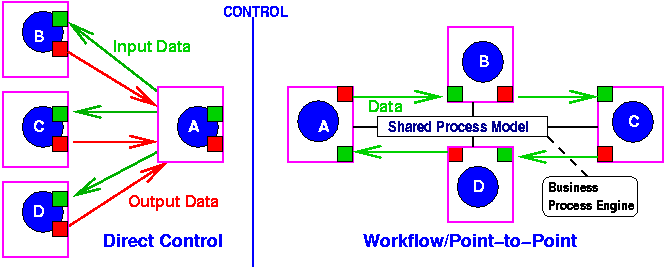
The WxFL models in particular, including WSCL, assume the process (composed of service interactions) is exactly workflow, the process can be described prior to execution, and a shared process model can be generated and used by a centralized process engine, such as BPWS429 or Collaxa30, to control process execution. BPEL4WS and its associated transaction models address some deficiencies of WSFL[Appendix D] but violate strongly both the democratic and just-in-time principles because web service integration is accomplished by a process graph with end-to-end connections that must be established in advance of execution. More fundamentally, the workflow approach is to define specific processes with specific messages among a set of pre-identified partners, not based on existing WSDL. Rather, new WSDL needs to be written in order to conform with the process, instead of using WSDL at runtime for integration.
This means that service providers must agree in advance to some shared model, kept and maintained by some entity, and have programmed the appropriate endpoint connections. Changing this shared model may mean reprogramming by the service providers, thus making dynamic service discovery, use, and integration for VEs impossible, as well as causing maintenance and scalability problems[Appendix B].
A point-to-point specification of connections presupposes a graph-based approach, but allowing more flexible transactions among the services can also be based on graphs. EbXML, BTP20, BPML7, and Rosettanet9, as well as the unimplemented WfMC[WFMC] standard, take more of a peer-to-peer transactional approach, but still none allow runtime discovery of new actors for roles or new activities, violating the just-in-time principle, because they all assume that all potential partners are identified prior to run time and that all concrete transitions can be enumerated and described in a process graph prior to runtime, or in the case of Rosettanet, specialized transactions agreed upon between partners. Such standards focus on specification of specific transactions among pre-identified partners, rather than generic transactions.
There are efforts underway by major vendors to provide XML-based EDI26 via SOAP/WSDL but may require a central process execution engine since the EDI standard does not now constrain the message dialog and the general flexibility of such systems remains to be seen. The Self-Serv system requires no centralized control engine for a given set of transactions as it generates distributed coordinations at runtime as needed. However, because of its focus on composition, its containers are still graph-based and thus also do not allow a completely free choice of services and providers at runtime.
Pre- and post-conditions are important any web service for operation sequencing, but crucial for one that performs an action, changing the world in some way. Further, if one had the pre-conditions and side-effects defined for each operation, one would not need a graph-like prescription of how to sequence the operations, such as WSCL. Software could automatically determine which operations require pre-conditions that are the effects of other operations. The post-conditions at least partially describe whether the service accomplishes what is required, such as whether food gets delivered when, whether a flight has been booked, or whether a component is promised for delivery by when. The pre-conditions tell us what services may be required in order to do any of these things with the target service. Pre-conditions may include providing a conversion of money, providing components to be shipped for assembly, reserving a room for the event to be catered, and any number of other conditions that would be achieved by other services.
The idea of connecting services and tasks by pre- and post-conditions at runtime has been a fundamental function of AI Planning[Allen et al] as well as simple type of project management[Petrie et al]. Condition-based integration may also use a workflow graph as a starting point, but allows runtime changes, as does the workflow system InConcert24. At the level of a specific application, condition-based integration provides a partial program for service integration, which can be usfully decomposed into goals that are not satisfied until services are found, and constraints that are not violated unless certain services are found[Petrie et al]. For example, the goal is to assemble a PC with certain requirements, and the constraints might be to avoid a certain supplier and keep the total cost below a given amount. The software is then free to plan a sequence of services that result in the PC being assemled under those constraints. Many possible plans are possible, so the program of service sequences is only partially specified by the goals and constraints.
Condition-based integration cannot be accomplished by point-to-point connections but rather requires peer-to-peer transactions. In addition to the WxFL data messages flowing across the network, there should be also monitoring and control messages used to coordinate and control of the application process, vs. control of the underlying transactions. In the most flexible case, there would be an Execution Control Language (ECL), similar to the Agent Communication Languages (ACLs)[Obrien and Nicol] that currently exist. This approach specifies only generic message types applicable to any process, which potentially allows any player communicating in the standard set of messages to play at any time, depending upon the authentication enforced. Like an ACL, a pure-to-peer ECL protocol would be an abstract partial program for many processes. The ECL protocol is an implicit abstract process model associated with the types of messages that determines only whether some message sequences are legal. Of course, there also has to be further agreement on the data content of the messages, based on standard XML-schemas, such as UBL.
In such an approach where an ECL is used for condition-based integration, each business partner is responsible for protocol enforcement. Each evaluates the received message and determines whether it is legal or not. Each is free to send back something like an ACL Sorry message, saying either - "I don't understand this message in this context" or "I reject your request." For instance, if A sends B a "Create-Order" that was not preceded by a "Firm-Order", then B would reject this message.
There is no need for the central process engine, with its maintenance and scaling issues. We still pass data, but augmented by a standard for the semantics of the data and what would be appropriate actions for this kind of data. For example, the data messages might be of types "Purchase-Order", "Firm-Order", "Acknowledge-PO", "Create-Order", and "Order-Fulfillment". This is similar to today's ACLs in that there are abstract generic messages types defined and legal protocols for exchanging these messages. In ACLs, something like a "Create-Order" is called a "performative". Here, let us just refer to "message types". These message types (along with the shared semantics) would tell the receiver what to do with the data contained in the message, thus adding a basic level of control to the process. Let us call these Action Control message types.
In addition to control messages already discussed, there is another flexible set of message types that allow dynamic negotiation, which would be useful in an RSN, as well as individual services. Suppose automatic software wanted to negotiate on the behalf of the user? How is one to use a discount coupon to get a cheaper rate, or to know to ask what the options are? How would a supplier agree to terms for delivery tentatively, based on other pending agreements, and later confirm or reneg on that agreement?
We can more-or-less directly use some other ACL message types for this, such as those of the "contract net" [Smith] protocol, as well as others12,13,14. Actually, extensions could enable a choice of negotiation protocols at runtime. In any case, ECL negotiation primitives for a given protocol will look something like solicit-bid, propose, accept / reject, commit / reneg, etc. These Negotiation Control message types add another level of control and have been implemented in a a commercial solution[Steiner & Kolb].
Although sufficient for dynamic process integration, Action and Negotiation Control messages are not sufficient for the ultimate consumer, and recursively for each consumer in the RSN, to predict, whether the process goals will be met on time, or at all, and to take action to correct the process when necessary. An integration of various services is a distributed process. This requires some form of distributed process management with language for process control and monitoring. The domain of this control and monitoring language is not the application itself but rather the process executing the application.
The alert reader will by now have noticed that we have not yet mentioned the status messages. We need feedback on the status of the RSN process and a way to fix any problems. Going back to workflow is one way to address this requirement, using XML to express a distributed workflow, with no central process engine[Muehlen],[Tolksdorf]. These particular systems are based upon the WfMC standard, which is not likely to be widely adopte and which has no standard for implementation evaluation. But the are "process" message types in these systems substantially increase the level of monitoring as well as control of the process.
There is good research to be done in this area, especially if one is not constrained by formats suggested by current vendors. As a naive start, consider these definitions of a hypothetical distributed "PXML" with ECL primitives "step" and "response":
Step has a step-name, the name of the prior step and the action that led to this one, the role of the sender(s) of this current step, the current action requested, one or more receivers of the next step, a reference to XML types in the body of the message to be acted on, a reference to any super-process of which this step may be a sub-process, and informal text to be included in any accompanying emails to the current recipient of the step.
Response defines the exception action that should be taken if a step is not performed as expected by a certain time and includes a list of people or programs to be notified.
With the right semantics and a very few other such simple XML tags, it would be possible to define, completely apart from the work to be done, descriptions of the process to be accomplished27 . Each actor may process the incoming process step information independently or there may be a host engine. In case of the former, it may be that each actor can modify the step as desired, so that new services and providers can be used at runtime. When a process step is not performed as defined, the response determines who should be notified. There are certainly technical issues to be worked out with this approach, but they are probably not as difficult to achieve as acceptance of a new way of doing business.
A crucial research question, as yet unexamined by any of these systems, is how to control the flow of status messages. This is crucial because different participants should have access only to certain information about the process status in order to know the process context. The issue of transparency is that they should have enough information to reliably and efficiently provide their services, but not enough to compromise the proprietary interests of the upstream consumers of these services. For instance, does one allow each actor to see the step just prior to the one to be executed? More? DAML-S, for example, does not yet address the issues of status monitoring and control, though it acknowledges them.
Maintaining the state of such a distributed process is also a difficult problem, but one for which known techniques exist, even for distributed planning and execution of tasks and services.[Petrie et al]. There are techniques in the software agent community for coordinating cooperative problem solving[Singh] and corresponding ACL primitives. Clearly a web service ECL could benefit from this prior work on Multi-Agent Systems (MAS).
A very advanced but important functionality is service integration planning[McDermott], [McIlraith&Son]. Suppose a US bank is managing the mortgage process (a web service application we are likely to see soon). It may be that there is a goal of insuring the house for $200K, which may not be possible, but a smart planning system will realize the goal can be decomposed into two subgoals of insuring for $100K each. Compensating transactions are insufficient for such cases.
There is a set of AI planning technologies that can address such problems, including replanning due to contingencies, such as a failure of a supplier to ship on time. Achieving explicit goals is a fundamental part of planning technology, such as in XSRL[Papazoglou et al]. And services will need to advertise pre- and post-conditions in order to use such planning techniques. This is particularly important when services have actions, which affect what next service is needed, including perhaps undoing the action just taken. For instance, a package that arrives too late may have to be returned.
So why not just use MAS technology? A major technical reason is that the fundamental problems of service discovery have not been solved by the academic approach. How does one find the capability one is looking for? How does one advertise? How can software do this on behalf of but without the intervention of a person? There have been many proposals along these lines, ranging from content-based routing in the early 90's15 to this year's use of DAML-S for agents16[Payne et. al]. But none of them led to deployed practical systems. DAML-S itself does not solve the discovery problem since it does not provide a standard ontology of business transaction "things", such as "payment".
Though the MAS community is now attempting to conform to the emerging WSxL/XML standards, and there are excellent efforts in this direction[Blake], we believe there is another approach that may succeed more quickly. (One of us said in 1998 that software agents were being left behind in e-commerce19.) And that is to see how web services may evolve into agents, rather salvaging the academic software systems.
A key issue is that a software agent accepts any text message from anyone else over the Internet and makes no commitment to the kind of response, or any future volunteered message. Part of the success of the WSxL approach has been to require services to be advertised as rather fine-grained operations that accept and generate only certain messages (and at specific addresses), which are readable in advance of sending messages.
Suppose that an ECL were implemented simply as WSDL operations. Each operation would describe its input and output messages, using XML complex types and a schema. This can be read by any other service considering sending a "Create-order", a "Step", or a "Commit-Action" ECL "message": actually using the appropriate ECL operation for that service. The sender can know what input message is appropriate and what output message to expect. This is in contrast to the general ACL approach in which each agent is expected to parse whatever is sent.
In [Petrie 2000], we described a methodology in which there was a web description of the messages each agent would send and receive. This was for the benefit of human agent developers in order to coordinate development. WSDL offers that possibility of machine readable message descriptions that can be understood at execution time, with some general standards and semantics that evolve in the business world.
As web services become more sophisticated in order to create VEs, as an ECL evolves, and as appropriate technologies from academia are incorporated, these web services will become effectively software agents themselves. We might call these new systems Service Agents. And we believe that such Service Agents, using an ECL to coordinate distributed processes, with no fixed process model, can be developed, and are necessary, in order to bring about the vision of dynamic Virtual Enterprises. But academics will need to build initially unsatisfying technologies. Combining DAML-S with UDDI is a very good example of such work[Paolucci etal]. But some academically uninteresting work is absolutely necessary. In particular, because there is no standard way to represent web service authorization, or payment, there are virtually no public web services that deliver real products, such as food, flight bookings, or car reservations.
To be clear, while there is a lot of excellent academic research being done in web services, with hard open issues, and the potential for important applications, we advocate that the academic software agent systems be discarded, except for research purposes, or unless "hidden" underneath the WSDL technology. Industry developers should look at the MAS technology and steal freely. MAS researchers who want to make a difference, should start from scratch and build on top of the emerging industrial web service technologies. One question about this approach that could be asked, and has been in lectures, is "why advocate throwing away good systems and developing on top of bad ones?" Because it has the advantage of never having been tried. Ignoring industrial technologies leads only to published papers, while ignoring well-studied advanced distributed computing principles can lead to slow industrial progress due to the necessity for re-invention based upon experience. A first step towards this is the collaboration between CommerceNet and the Stanford Center for Information Technology that is producing workshops with industry on the topics of this paper: the first one was "Business Service Registry Workshop".
Footnotes
1 Yodlee: http://www.yodlee.com
2 WSDL 1.1: http://www.w3.org/TR/wsdl
3 DAML-S http://www.daml.org/services/
4 TAP http://tap.stanford.edu
5 WSCL 1.0 http://www.w3.org/TR/wscl10/
6 ebXML http://www.ebxml.org/
7 BPML http://www.bpmi.org/bpml.esp
8 XLANG http://www.gotdotnet.com/team/xml_wsspecs/xlang-c/default.htm
9 RosettaNet http://www.rosettanet.org/rosettanet/Rooms/DisplayPages/LayoutInitial
10 WSIL 1.0 http://www-106.ibm.com/developerworks/webservices/library/ws-wsilspec.html
11 WSFL 1.0: http://www-4.ibm.com/software/solutions/webservices/pdf/WSFL.pdf
12 Service-Oriented Negotiation http://www.ecs.soton.ac.uk/~nrj/so-neg.html
13 MAGNET (Multi AGent Negotiation Testbed) http://www.cs.umn.edu/magnet/
14 FX-Agents http://fxagents.stanford.edu
15 Content-based Router http://www-ksl.stanford.edu/knowledge-sharing/agents.html
16 Semantic Matchmaker http://www-2.cs.cmu.edu/~softagents/daml_Mmaker/daml-s_matchmaker.htm
17 BPEL4WS http://www-106.ibm.com/developerworks/library/ws-bpel/
18 UDDI http://www.uddi.org/specification.html
19 IATA 1998 http://www-cdr.stanford.edu/~petrie/agents/agent-ec/
20BTP 1.0 http://www.oasis-open.org/committees/business-transactions/
21 SWWS http://swws.semanticweb.org/
22 WSCI http://wwws.sun.com/software/xml/developers/wsci/
23 Dollar Rent A Car Case
http://groups.haas.berkeley.edu/citm/conferences/020612/presentations/Segev+Patankar.pdf
and
http://www.microsoft.com/resources/casestudies/CaseStudy.asp?CaseStudyID=11626
24 TIBCO Products http://www.tibco.com/solutions/products/default.jsp?m=b4
25 UN/EDIFACT http://www.unece.org/trade/untdid/welcome.htm
26 XML/EDI http://www.geocities.com/WallStreet/Floor/5815
27 PXML http://www-cdr.stanford.edu/~petrie/fx-agents/xserv/pxml.html
28 UBL http://www.oasis-open.org/committees/ubl/
29 BPWS4 http://www.alphaworks.ibm.com/tech/bpws4
30 Collaxa httP://www.collaza.com
Citations
[Allen et al] Allen, Hendler, and Tate, eds., Readings in Planning, Morgan Kaufmann, 1990.
[Blake] B. Blake, "Towards the Use of Agent Technology for B2B Electronic Commerce", unpublished, http://www.cs.georgetown.edu/~blakeb/AgentB2B/blake_AgentB2B_Position.pdf
[Benatallah et al] B. Benatallah, Q. Sheng, M. Dumas, "The Self-Serv Environment for Web Services Composition," IEEE Internet Computing, Jan/Feb 2003, 7,1, pp. 40-48
[Curbera] F. Curbera et al., "Unraveling the Web Services Web: An Introduction to SOAP, WSDL, and UDDI ",IEEE Internet Computing, Mar/Apr 2002 6,2, pp. 86-93
[McDermott] D. McDermott "Estimated-Regression Planning for Interactions with Web Services", Proceedings of the AI Planning Systems Conference (AIPS'02), June 2002.
[McIlraith&Son]
S. McIlraithand T. Son,
"Adapting Golog for Composition of
Semantic Web Services,"
Proceedings of the Eighth International Conference on
Knowledge Representation and Reasoning (KR2002),
Toulouse, France,
April, 2002.
See also
http://www.daml.org/services/mci-son-kr02.ps
[Muehlen] M. zur Muehlen, F. Klein,
"AFRICA: Workflow Interoperability based on XML-messages",
CAiSE 2000 Workshop on Infrastructures for Dynamic
Business-to-Business Service Outsourcing (ISDO '00). Stockholm,
Sweden, June 5-6, 2000. See also
http://www.wi.uni-muenster.de/is/mitarbeiter/ismizu/MIZU.FLKL-AFRICA(CAiSE2000).PDF
[Obrien and Nicol]Obrien and
Nicol,
"FIPA - towards a standard for software agents",
BT Technology Journal, 16, 3, July 1998,
pp. 51-69.
See also
http://www.sc-server1.bt.com/bttj/vol16no3/06.pdf
[Papazoglou et al] M. Papazoglou, M. Aiello, M. Pistore, and J. Yang, "XSRL: An XML Web-Services Request Language", Technical Report #DIT-02-0079, University of Trento, Povo, Italy, 2002. See also http://www.ebpml.org/xsrl.zip
[Payne et al] Payne, Singh, and
Sycara. "Calendar
Agents on the Semantic Web." IEEE Intelligent
Systems, 17(3), pp. 84-86, May/June 2002.
Also appears in IEEE
Distributed Systems Online, 3(5), 2002.
available at
http://dsonline.computer.org/0205/departments/sem.htm
See also
http://www-2.cs.cmu.edu/~softagents/papers/84-86.pdf
[Paolucci et al]
M. Paolucci, T. Kawamurra, T. Payne, K. Sycara,
"Importing the Semantic Web in UDDI,"
Forthcoming in Proc. of Web Services,
E-business and Semantic Web Workshop, 2003,
http://www.softagents.ri.cmu.edu/papers/Essw.pdf
[Petrie 1998] C. Petrie,
"The XML Files",
IEEE Internet Computing, 2(3) May-June 1998,
available at
http://www-cdr.stanford.edu/~petrie/online/v2i3-webword.html
[Petrie et al] Petrie, Goldman, and Raquet,
"Agent-Based Project Management", Lecture Notes in AI - 1600,
Springer-Verlag, 1999.
See also
http://www-cdr.stanford.edu/ProcessLink/papers/DPM/dpm.html
[Petrie 2000] C. Petrie,
"Agent-Based Software Engineering",
Proc.
PAAM 2000, Manchester, April, 2000,
published in
Agent-Oriented Software Engineering, Eds. P
Ciancarini and M. Wooldridge, Lecture Notes in AI 1957,
Springer-Verlag, 2001.
See also
http://nrc.stanford.edu/~Petrie/agents/abse/abse.html
[Singh] M. Singh,
"Be Patient and Tolerate Imprecision: How
Autonomous Agents can Coordinate Effectively (",
Proc. Internat. Joint Conference on Artificial
Intelligence (IJCAI), August 1999, pp 512-517.
See also
http://www.csc.ncsu.edu/faculty/mpsingh/papers/mas/ijcai-99.ps.gz
[Smith] R. G. Smith, "The Contract-Net Protocol: High-Level Communication and Control in a Distributed Problem Solver", IEEE Transactions on Computers, 29,12, pp. 1104-1113, 1980.
[Steiner & Kolb] D. Steiner, M. Kolb, "Enabling Business Process Connectivity", WebV2 available at http://www-cdr.stanford.edu/~petrie/fx-agents/xserv/webv2.pdf
[Tolksdorf] R. Tolksdorf, "Workspaces: A Web-Based Workflow Management System", IEEE Internet Computing, 6(5) September-October 2002.
[Trivedi] R. Trivedi,
"The Role of Taxonomies in UDDI: tModels
Demystified,"
http://www.developer.com/java/print.php/10922_1367781_2
[Vinoski] S. Vinoski "Web Services Interaction Models Part 1: Current Practice",Internet Computing, May/June 2002 6,3, pp. 89-81
[WFMC]
"Workflow Management Coalition
Workflow Standard - Interoperability
Wf-XML Binbding"
http://www.wfmc.org/standards/docs/Wf-XML-1.0.pdf
[Appendix A] :
Critique of WSDL as a Language
Definition
http://www-cdr.stanford.edu/~petrie/fx-agents/xserv/icpaper/appendix-a.html
[Appendix B] : Critique of WSxL
pIntegration
http://www-cdr.stanford.edu/~petrie/fx-agents/xserv/icpaper/appendix-d.html